
2026年7月6日
Tesla
6分
テスラの低電圧バッテリーが死んだら、ドアも充電ポートも開かなかった
金曜夕方、1時間前まで普通に乗れていたテスラが突然無反応になった。スマホキーもカードキーもキーフォブも効かず、充電ポートも開かない。原因は低電圧バッテリーだった。...
金曜夕方、1時間前まで普通に乗れていたテスラが突然無反応になった。スマホキーもカードキーもキーフォブも効かず、充電ポートも開かない。原因は低電圧バッテリーだった。...

Hermes AgentのバックエンドをローカルQwenに寄せて試したときに感じた、低リスク作業と副作用ありタスクの信頼性の差についての実験ログです。...
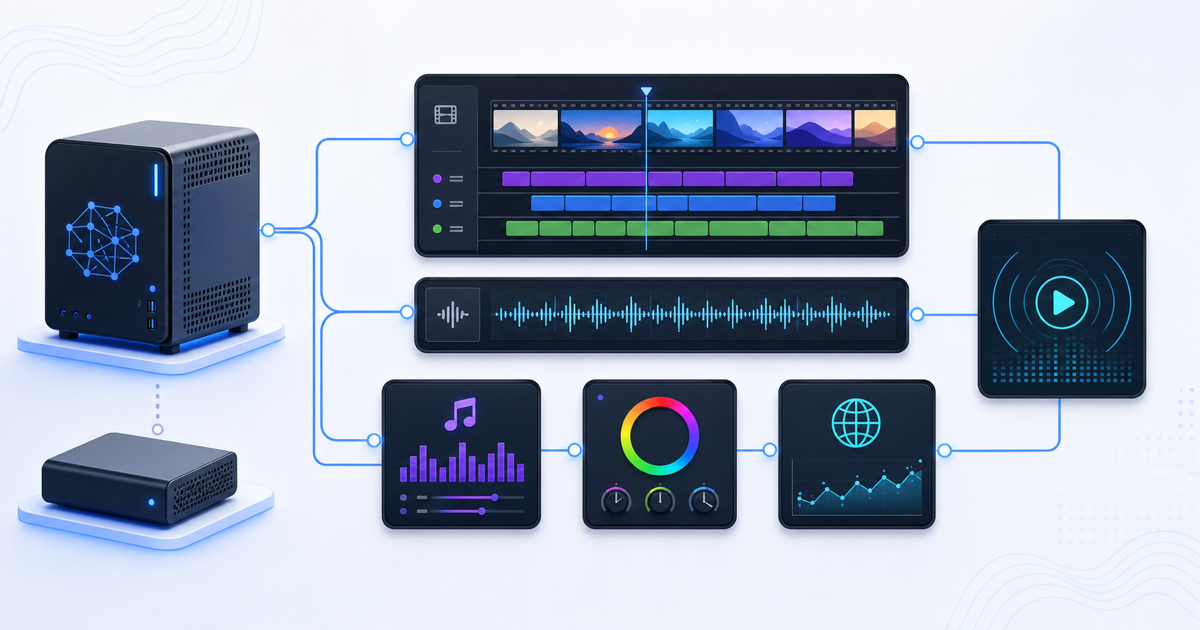
インデックス済みの写真と動画から、Qwenのクリップレビュー、STT、人物識別、BGM、LUT、HLSを組み合わせて自動Vlog生成を試した記録です。...

写真サムネイル、動画キーフレーム、STT、EXIF/GPS、人物ラベルを組み合わせて、家庭内メディアを自然言語で検索できるようにした実装メモです。...

外付けストレージにたまった家庭内の写真と動画を、GX10上のQwen、STT、顔検出、SQLite検索でローカルAIメディアライブラリ化する開発記録です。...

Opus 4.7とGX10 Qwenが作った同じSwiftUI電卓アプリのソースを読み、見た目の差がどの制約や状態管理に出ていたのかを確認した。...