Article
写真と動画から自動Vlogを作る ローカルAI動画生成パイプライン
GX10 Galleryで一番わかりやすく楽しい機能は、イベント動画の自動生成だ。
写真と動画を検索できるようにするだけでも便利だが、最終的にはイベント単位で1本の動画として見返したい。旅行イベント、水族館イベント、公園イベント、キャンプイベント。素材はたくさんある。ただ、毎回編集ソフトを開いて、クリップを選び、並べ、BGMを入れて書き出すのはそれなりに手間がかかる。
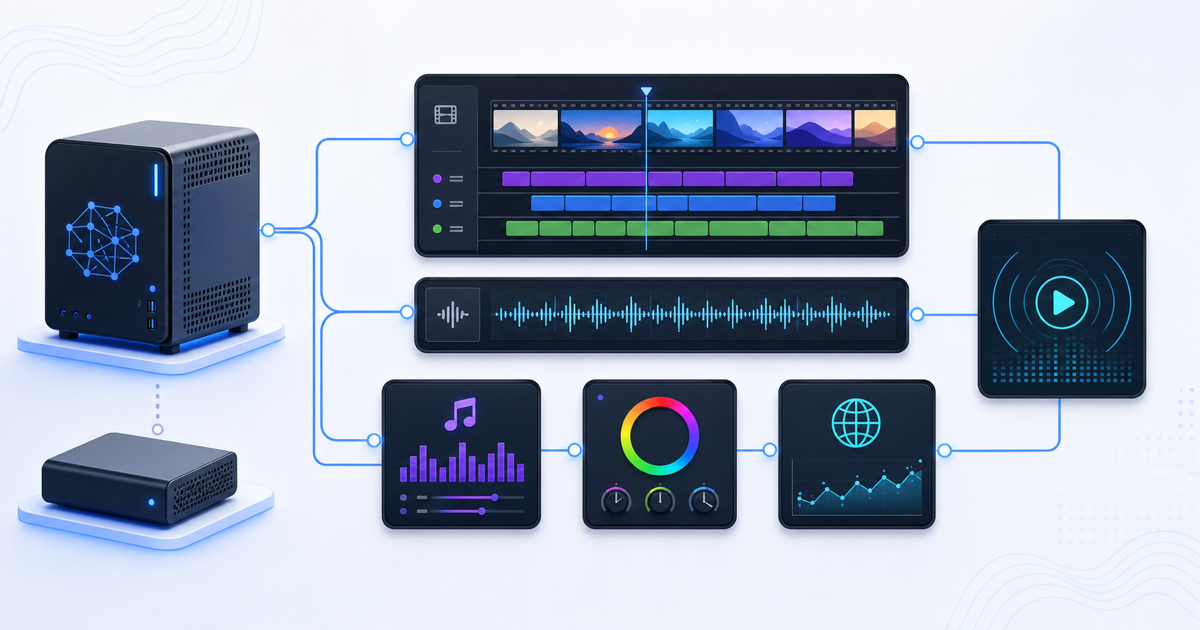
そこで、GX10 Galleryではインデックス済みの写真と動画から、自動でVlog風のダイジェストを作るようにした。
現時点では、プロの動画編集AIではない。テンポもストーリーもまだ改善したいところが多い。それでも、ローカルAIとルールベースを組み合わせると、「イベントをざっと見返す動画」としてはかなり面白いところまで来た。
全体の流れはこうだ。

動画を中心に組む
最初は、写真と動画を混ぜながら短いダイジェストを作っていた。
ただ、見返してみると少し物足りなかった。クリップが少なすぎる。写真が途中に多く入りすぎる。似た場所の写真が何枚も続く。動画として見るなら、まず動画を中心にした方が自然だった。
そこで方針を変えた。
1. 動画クリップを中心に時系列で並べる
2. 良さそうな動画クリップはなるべく多めに入れる
3. 最後に写真を3から5枚ほど入れて余韻を作る
4. BGMを入れる
5. 元動画音声も残す
6. 4Kで書き出す
イベントによっては、少し長くなってもいいことにした。素材が多いのに無理に短くすると、見どころを落としすぎる。特に旅行イベントや一日イベントでは、多少長くても、ちゃんと場面が残っている方が見返しやすい。
クリップ候補を作る
動画生成では、まず候補クリップを作る。
動画ファイルごとに、何秒あたりから何秒使うかを決める。撮影日時があれば時系列を保つ。イベント内の動画をざっと並べ、その中から使えそうな区間を切り出す。
候補作成では、次のような信号を使っている。
- 動画の長さ
- キーフレームのQwen説明
- 短い音声区間のSTT結果
- 匿名化した人物ラベル
- 撮影日時
- ブレや向きの品質チェック
- 似た場面が続かないか
完全にQwen任せにはしていない。短すぎる動画、真っ暗な場面、天地逆転している場面、明らかにブレが強すぎる場面は、ローカルなルールで落としたい。
一方で、何が良い場面かはルールだけでは決めにくい。子どもが反応している場面、家族メンバーの会話がある場面、イベントらしい風景がある場面は、QwenやSTTの方が手がかりを持っている。ここはルールとAIを混ぜた方が扱いやすかった。
Qwenで弱いクリップを落とす
実装中にわかりやすかったのが、横倒しや天地逆転のクリップだ。
スマホやカメラの向き、メタデータ、撮影中の動きによって、見返すと「これは使いたくない」というクリップが混ざる。人間なら一瞬でわかるが、単純なスコアでは拾いにくい。
そこで、採用候補になったクリップをQwenにレビューさせる。
レビューでは、次のような観点を見る。
- 被写体が見えるか
- ブレが強すぎないか
- 暗すぎないか
- 天地逆転や横倒しではないか
- 同じような場面が続きすぎていないか
- イベントの流れに対して意味があるか
Qwenの判断だけで全てを決めるわけではないが、「これはやめた方がよい」という候補を落とすにはかなり役立つ。
最初のころは、床が大きく写った横倒しのクリップが動画に入ってしまった。こういうものを人間が見つけて、ロジックに戻し、Qwenレビューを入れていく。ローカルAIなので、こうした試行錯誤を何度もできる。
STTで会話を拾う
動画の良し悪しは、映像だけでは決まらない。
家庭内動画では、音声がかなり大事だ。誰かの反応、笑い声、会話、イベントの音。映像としては地味でも、音があると残したくなる場面がある。
そこで、動画から短い音声窓を取り出し、STTにかける。文字起こしに会話や反応が入っていれば、クリップ候補として加点する。
もちろん、全動画の全音声を細かく解析するわけではない。まずは短い窓をいくつか見る。完璧ではないが、会話のある動画を拾うには十分に効く。
人物識別は公開情報にしない
イベント動画では、誰が写っているかも重要だ。
単に景色だけが続くより、家族メンバーが写っている方がVlogらしい。そこで、顔識別でラベルが付いた人物が写っているクリップを加点する。
ただし、公開記事では人物名は出さない。内部的には人物ラベルを使っていても、本文では人物A、人物B、家族メンバー、子どものように丸める。今回も実スクリーンショットは使わず、ヘッダー画像と図はすべて生成または抽象化したものにした。
顔識別は、動画から切り出したフレームにも適用できる。写真と動画で基本的には同じだ。動画もフレームを切り出せば、顔検出の対象になる。
写真は最後に入れる
写真の扱いも調整した。
最初は、動画の途中に写真を差し込んでいた。ただ、写真が何枚も続くとテンポが変わる。しかも、同じ場所で画角違いの写真が続くと、ダイジェストとしては少し退屈になる。
そこで、写真は基本的に最後に入れることにした。
イベントの最後に、良さそうな写真を3から5枚入れる。集合写真、印象的な表情、イベントらしいカット、明るく見やすい写真を選ぶ。RAWとJPGが同名で両方ある場合は、動画生成にはJPGを採用する。RAWそのものを動画に使うより、既に現像されたJPGの方が見た目が自然だからだ。
似た写真が続かないように、多様性ガードも入れた。同じ場所、同じ構図、同じ被写体が連続しすぎないようにする。
BGMと元音声
BGMはローカルの音楽ライブラリから選ぶ。
最初は単純に1曲をループしていた。これでもそれなりに見られるが、イベントの雰囲気に合う曲を選びたい。そこで、BGM候補のメタデータやイベントの説明をQwenに渡して、合いそうな曲を選ぶようにした。
元動画の音声も残す。
ただし、クリップ自体にすでにBGMが乗っている場合がある。たとえば、イベント会場の音楽が大きく入っている動画だ。そこに別のBGMを強く重ねると音が濁る。現時点では完全ではないが、元音声の状態に応じてBGM音量を下げる、あるいはそのクリップでは控えめにする方向で調整している。
クリップの切り替わりで音がブチッと聞こえることもあった。これは音声のフェード不足や切り出し位置の問題で起きる。短いaudio fadeを入れて、つなぎ目をなめらかにするようにした。
S-Log3とLUT
SONY FX3で撮った動画には、S-Log3とS-Cinetoneが混ざっている。
S-Log3のまま使うと、生成動画の色が眠く見える。そこで、動画メタデータからS-Log3かS-Cinetoneかを判定し、S-Log3にはSony LUTを当てるようにした。
方針は単純だ。
S-Log3:
LUTを当てる
S-Cinetone:
そのまま使う
これだけで、生成動画の見た目はかなり良くなった。AIで全部を決めるより、カメラプロファイルのように確実に取れる情報は普通のルールで処理した方が安定する。
HLSでWebから見る
生成した動画はWeb UIから見たい。
単純にMP4を返すだけでも再生はできるが、長い4K動画ではHLSの方が扱いやすい。そこで、生成後にHLSも作るようにした。
Web UI側ではHLSを優先して再生する。HLSがない場合にMP4へその場で逃がすより、生成キューに入れてHLSを作る方針に寄せた。動画生成後は、MP4とHLSをセットで揃える。
動画生成は重い。4Kで書き出すし、ffmpegも走る。だから、Webからキューに入れて、順番に実行する方式にした。
また、生成した動画を次回の素材に混ぜないようにする必要がある。イベント配下にoutputやoutputsのようなディレクトリがある場合、その中の動画は次の動画生成のクリップ候補から外す。これを忘れると、前回生成したダイジェスト動画が素材として再利用され、変な再帰が起きる。
ローカルAIでよかったこと
この機能は、実装中に何度も再処理した。
クリップが少なすぎる。写真が続きすぎる。BGMが合わない。色が眠い。横倒しクリップが入る。顔識別の結果をもっと使いたい。場所名を説明文に反映したい。Render途中のイベントではボタンを押せないようにしたい。
こういう改善をするたびに、Qwen、STT、embedding、顔検出を使う。
クラウドAPIでやっていたら、かなり気を使ったと思う。処理量も多いし、個人メディアでもある。ただし、ここでは正確なコスト計算はしていないので、金額として何円得をしたとは書かない。実感として大きいのは、失敗しても何度でも回せることと、家庭内メディアを外に出さずに済むことだ。
実際、バックフィルは数百イベント、数万メディア規模で走っている。すぐには終わらない。でも、AIが常に限界というより、丁寧に直列で処理している部分が多い。ローカルで回し続けられるので、少しずつ改善しながら育てられる。
まだ完成ではない
まだやりたいことは多い。
- イベントの写真フォルダと動画フォルダのマッチング補正
- クリップ選定のテンポ改善
- もっと自然な場面転換
- 既存BGM入りクリップの検出精度向上
- 人物ごとの登場バランス調整
- 旅行イベントのような長い素材の章立て
- Web UIからの再生成設定
ただ、土台はできた。
写真と動画を検索できる。人物や場所で探せる。イベントを開いてプレビューできる。ボタンを押すと、自動でVlog風の動画ができる。
ローカルAI専用機としてのGX10は、こういう用途にかなり向いていると思う。ベンチマークよりも、生活の中にある大量データを相手にした時の方が、価値がわかりやすい。